
 Melky
Melky 
Why you don't rank pages with links: The shift to topical authority
The Penguin Update fundamentally changed the way we build links, shifting the focus from mathematical exploitation to semantic authority.
Before this shift, SEO strategies relied on simple mathematical manipulation.
If a publisher used the anchor “toilet seats” repeatedly across dozens of backlinks, the target page would rank for that specific string regardless of its actual quality.
This mechanism exploited the simplicity of early Information Retrieval systems which lacked semantic understanding.
The 2012 Penguin Update changed everything by penalizing websites that utilized these over-optimized anchor text profiles.
Google’s algorithms shifted from treating raw link counts as votes to detecting unnatural patterns, rendering exact-match keyword stuffing obsolete and establishing “pattern detection” as the primary filter for off-page signals.
Modern algorithms utilize Machine Learning to identify these statistical anomalies.
A link profile containing 80% exact-match anchors deviates from the natural distribution of the open web, triggering spam classifiers.
This shift away from raw link counts raises an important question: if individual page links no longer work the same way, what does?
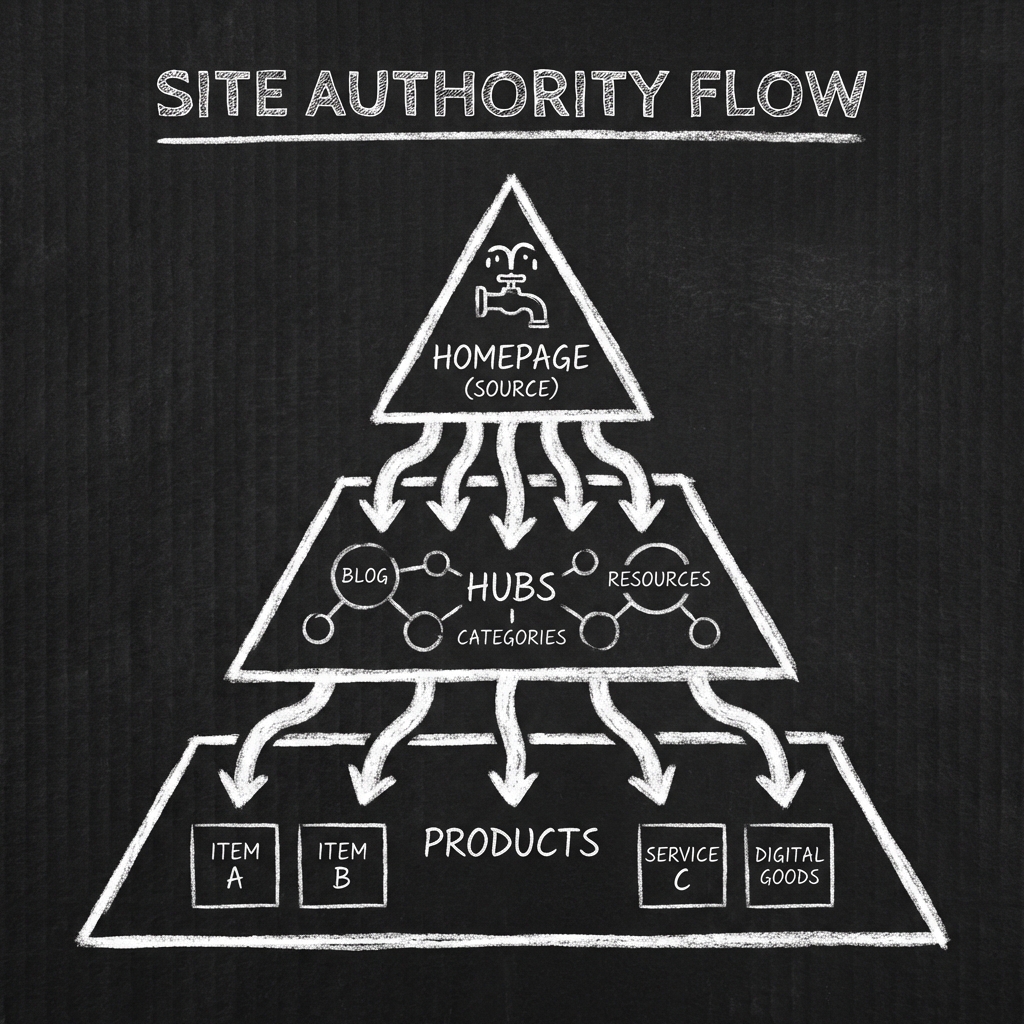
The difference between Page Rank and Site Authority?
Page Rank measures the widespread connectivity of a single URL, whereas Site Authority represents the cumulative trustworthiness of an entire domain.
Modern Information Retrieval systems prioritize Site Authority, utilizing internal link architecture to distribute “equity” from the homepage to child pages naturally.
The concept of “ranking a page” functions as a misnomer in Semantic SEO. Search engines evaluate the source domain before evaluating the individual document.
- Old Model: Build links to a specific URL to boost that URL.
- New Model: Build links to the domain to boost the entire semantic graph.
A robust site architecture functions as a distribution network. Link equity flows from the homepage (root node) through category pages (hub nodes) to product pages (leaf nodes).
This topology ensures that a single high-quality backlink strengthens thousands of internal ranking signals simultaneously.
Understanding site authority is critical, but how does Google actually interpret the signals within those links?
How does Google use anchor text in 2026?
Google utilizes anchor text to learn “new information” about a verified entity.
Instead of counting keyword repetitions as a ranking signal, the algorithm parses anchors as attribute definitions to augment the entity’s attributes in the Knowledge Graph.
Repeating the anchor “toilet seats” provides zero new information to an engine that already understands the page is about toilet seats. This redundancy increases calculation costs without adding value.
However, an anchor such as “toilet seats that Tom Belfort loves” introduces a subject-attribute-value connection.
- Entity: Toilet Seat.
- Attribute: Endorsement/Preference.
- Value: Tom Belfort.
This “Context Augmentation” allows the engine to rank the page for complex queries like “Tom Belfort recommended toilet seats,” derived entirely from the external signal.
Given this semantic approach to anchor text, the real competitive advantage doesn’t come from building links to individual pages it comes from how you structure your entire site.
Why is site architecture more important than backlinks?
Site architecture dictates the efficient distribution of link equity (PageRank) and semantic relevance.
A semantic hierarchy allows a few high-quality homepage links to propagate authority to thousands of product pages, eliminating the need for expensive, risky page-level link building. This is why technical SEO and site structure are foundational to modern search.
Data from large-scale e-commerce and SaaS audits confirms this distribution model.
A domain with 10,000 pages does not require 10,000 distinct backlinks. It requires a logical internal graph that minimizes the distance from the root node to the leaf nodes.
- Homepage: Receives external authority (trust injection).
- Categories: Distribute authority and define macro contexts.
- Products: Inherit authority and define micro contexts.
With this hierarchical model in mind, the natural next question becomes: where should you actually point your external links?
How should you distribute external links?
External links should primarily target the Homepage and Category Hubs.
This “Top-Down” distribution mimics natural citation patterns, allowing the internal semantic graph to funnel authority to specific leaf nodes without triggering spam classifiers.
A natural link profile follows a biological distribution:
- Homepage: 70-80% of links (brand citations).
- Hub Pages/Blog: 15-20% of links (informational references).
- Product Pages: <5% of links (specific citations).
Forcing “super strong” links directly to a deep product page creates an “inverted pyramid” structure, which signals manipulation.
Now that we’ve established the theory, here’s a practical framework you can implement immediately.
Actionable strategy: The link sprint protocol
A “Link Sprint” is the synchronized acquisition of external citations during a content publication spike.
This velocity match signals a “breakout entity” or “trending topic” to the algorithm, validating the sudden increase in both content and authority simultaneously.
Content velocity and link velocity must correlate. Publishing 100 pages while acquiring 0 links signals “content farm.” Acquiring 100 links while publishing 0 pages signals “link spam.”
Synchronizing these two velocities proves to the algorithm that the entity is active, relevant, and authoritative.
To execute this strategy without triggering spam filters, follow this 4-phase protocol:
Phase 1: The topical map (Preparation)
Before building a single link, you must define the destination.
Create a cluster of 20-50 interconnected articles that cover a specific “micro-semantic context” (e.g., “bamboo toilet seats”).
- Root: 1 pillar page.
- Branches: 5 sub-pillars for specific attributes (sizes, materials, installation).
- Leaves: 15-20 specific question/answer pages.
Phase 2: Velocity synchronization (The trigger)
The algorithm detects “anomalies.” You must fabricate a positive anomaly.
- Content velocity: Publish all 20-50 pages within a 48-hour window. This creates a “freshness spike.”
- Link velocity: Simultaneously acquire 5-10 high-power links to the Homepage and Category Hub.
Critical rule: Do not build links to the new leaf pages. Let the internal PageRank flow from the Homepage to the new cluster naturally.
Phase 3: The “News” classifier

When you match content velocity (200% increase) with link velocity (200% increase), you force Google to classify the anomaly as “News/Trend” rather than “Spam.”
- Spam signal: High link velocity + low content velocity.
- Trend signal: High link velocity + high content velocity.
Phase 4: Indexing & Validation
Force index the new content immediately using the Indexing API.
The timestamp of the external links must closely match the timestamp of the content publication. This “temporal co-occurrence” confirms the validity of the trend.
These principles become even more critical when we consider the rise of AI-powered search or Answer Engines like ChatGPT and Gemini.
How does this apply to AI chatbots and LLMs?
The rise of Large Language Models (LLMs) like ChatGPT and Gemini reinforces the necessity of the site authority model over page-level link building.
These systems utilize Retrieval-Augmented Generation (RAG) to ground their answers in factual data, prioritizing information reliability over simple link counts.
AI chatbots function as “answer engines,” not “search engines.” They maximize the probability of accuracy.
- Source domain verification: LLMs evaluate the trustworthiness of the domain (entity) before ingesting the content. A product page on a high-authority domain is treated as “trusted training data.” The same page on a low-authority domain (even with spam links) is treated as “noise.”
- Context window efficiency: The “zero fluff” rule reduces the token cost for the LLM to process your page. Clean, structured data (subject-action-value) is chemically easier for an AI to parse and cite.
- Attribution consensus: Chatbots cite the “consensus source.” By focusing links on the Homepage/Hubs to build Domain Authority, you position your entire site as a verified node in the Knowledge Graph. This increases the mathematical probability of your brand being selected as the citation for queries in your niche.
If you focus on ranking individual pages with artificial links, you optimize for a 2010 crawler. If you optimize Site Architecture and Domain Authority, you optimize for the 2026 AI retriever.
These aren’t just theories they’re backed by specific patents and frameworks that define how modern AI systems select sources.
Scientific basis: The AI patents
The shift from “search” to “answer” is not theoretical; it is encoded in specific Google patents that define how Generative AI selects its sources.
Understanding these patents does not require a computer science degree. Think of them as the “rulebook” that AI follows when deciding who to trust.
1. RAG & grounding (The reliability patent)
- Patent support: US20240346256A1 (Response generation using a retrieval augmented AI model).
This patent describes how an AI retrieves “trusted training data” to augment its prompt. It explicitly filters out “noise” (low-authority pages) to prevent hallucinations.
If your domain authority is low, you are filtered out of the “augmented prompt,” meaning ChatGPT will never cite you, regardless of your backlinks.
What is RAG?
RAG stands for “Retrieval Augmented Generation.”
In plain English: before an AI like ChatGPT answers your question, it first “retrieves” information from trusted sources to make sure its answer is accurate.
Imagine a journalist writing an article. A good journalist does not just write from memory they call trusted experts, check official databases, and verify facts before publishing.
RAG is the AI doing exactly this: calling its “sources” before answering.
How the patent works:

- You ask ChatGPT: “What is the best hotel in Bali?”
- The AI does not just guess. It queries a database of “trusted sources.”
- Low-authority websites (spam, thin content) are filtered out as “noise.”
- High-authority websites (known brands, expert sites) are kept as “trusted data.”
- The AI builds its answer using only the trusted data
If your website has low Domain Authority, you are filtered out at Step 3.
The AI will never see your content, no matter how many backlinks you have to a single page. Your entire domain must be trusted first, as E-E-A-T acts as the AI’s primary filter.
2. Candidate scoring (The reputation patent)
- Patent support: US9940367B1 (Scoring candidate answer passages).
This patent assigns a “reputation score” to a resource before extracting an answer. A high reputation score allows the system to trust the entity’s facts.
“Reputation” is a Domain-Level metric. You cannot “fake” a reputation score with spam links to a single leaf page.
What is candidate scoring?
When Google or an AI finds multiple pages that could answer a question, it needs to choose one. This patent describes how it assigns a “reputation score” to each source before picking a winner.
Think of a job interview. Two candidates have the same skills on paper. But one comes from a respected company (Harvard, Google), and the other comes from an unknown startup.
The interviewer unconsciously trusts the first candidate more. Reputation precedes the individual.
How the patent works:
- The system finds 10 pages that could answer “Best time to visit Japan.”
- Each page’s “domain” is assigned a reputation score (based on history, links, user behavior).
- Pages from high-reputation domains are prioritized.
- The answer is extracted from the highest-scoring source.
Reputation is calculated at the domain level, not the page level. You cannot build spam links to one product page and expect that page to “earn” reputation.
Your entire website must build trust over time. This is why investing in homepage and hub links (as described earlier) is the only sustainable strategy.
3. Fact Consensus (The Grounding Benchmark)
- Framework support: Google DeepMind’s “FACTS Grounding” Benchmark.
Google evaluates LLMs based on their ability to attribute claims to “Consensus Sources.” This is a critical aspect of AI search, as it ensures that the information provided is reliable and verifiable.
To be cited, you must be the “Consensus Source” (The Origin). Repeating facts makes you a copy; originating facts makes you the Authority.
What is fact consensus?
Google DeepMind created a public benchmark to test how well AI models “ground” their answers in verifiable facts.
A key metric is: “Can the AI attribute its claim to the “original source” of the information?”

Imagine a game of “Telephone.” The original message is “The sky is blue.” By the time it reaches the 10th person, it becomes “The ocean is green.” Google wants to cite Person #1 (the Origin), not Person #10 (the Copy).
How the framework works:
- You ask the AI: “What is the boiling point of water?”
- The AI must provide an answer and cite where it learned this fact.
- If the AI cites Wikipedia (which cites a textbook, which cites a scientist), it traces back to the consensus source, the original authority.
- Web entities that originate facts (publish original research, data, or definitions) are identified as authorities.
- Web entities that repeat facts (rewrite existing content) are identified as copies.
To be cited by AI, you must be an “origin” not a “copy.” This means:
- Publish original data, surveys, or case studies.
- Define terms in your niche before competitors do.
- Be the first to answer emerging questions.
Repeating what Wikipedia already says will never make you the Consensus Source.
Conclusion
The strategy of “ranking pages with links” relies on obsolete retrieval mechanisms.
Modern SEO optimizes the “Topical Authority” of the domain and uses “Site Architecture” to distribute that authority. The goal is not to rank a page, but to position the Brand as the Consensus Source for the entire topic.
This is part of the “AI Search? It’s Just Search, Rebranded” series.
Share Article
If this article helped you, please share it with others!
Some content may be outdated