
 Melky
Melky 
Mining exploratory queries: The horizontal search protocol
Current search systems are biased toward a narrow focus, despite data showing that nearly half of all search behavior is exploratory. Based on the research by Wenhan Liu and Yutao Zhu, I will explore the concept of “Horizontal Search” as the missing half of the user journey.
Mining exploratory queries: The horizontal search protocol
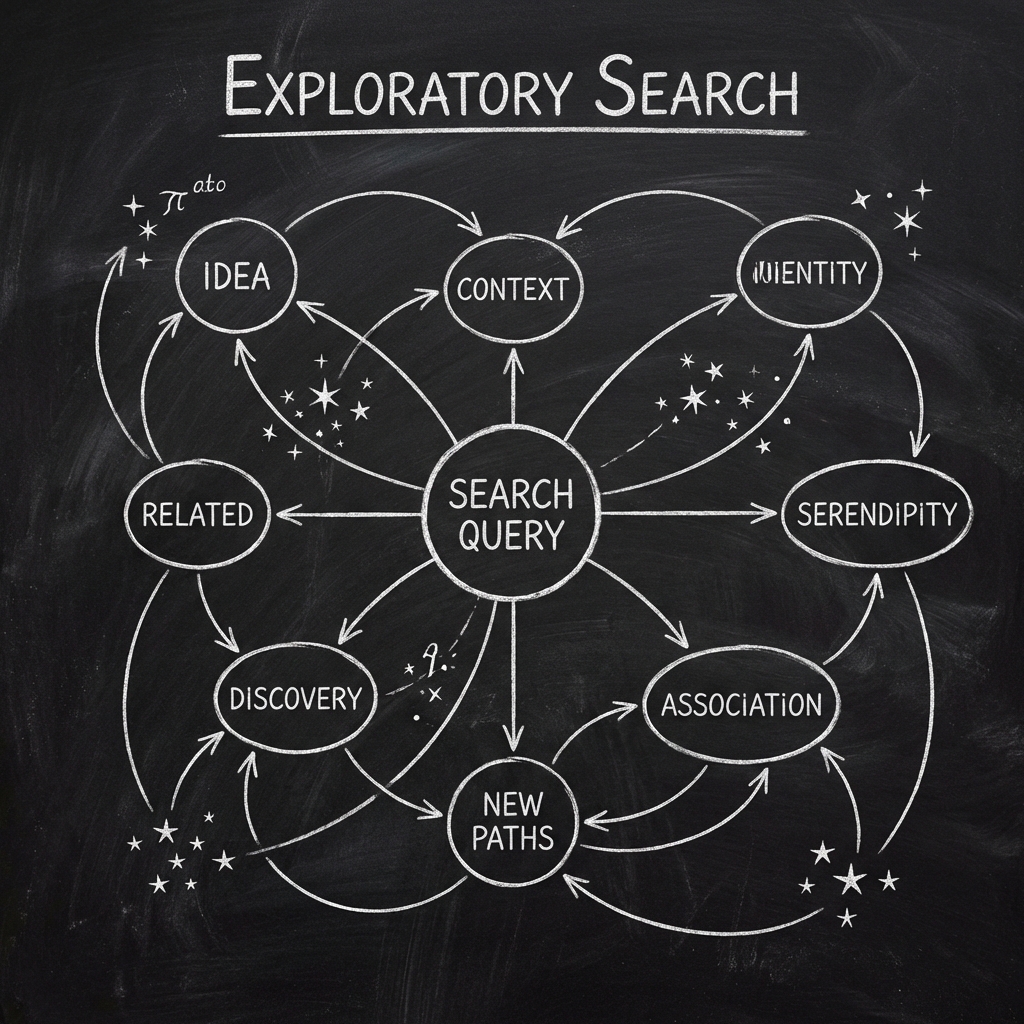
Exploratory query mining is the computational process of identifying and suggesting parallel topics that diverge from a user’s initial search intent.
Current systems focus on clarification, which narrows a topic, whereas this protocol focuses on exploration, which widens it. I view this as the mechanism that transforms a search engine from a fetch tool into a recommendation engine.
Exploratory Search is the user behavior of seeking parallel information paths rather than narrowing a specific focus. While traditional search engines force users into a “Tunnel Vision” of clarification (drilling down), the intelligent system anticipates the desire to branch out horizontally (expanding).
Exploratory search represents a fundamental shift in User Intent modeling. Because search engines with LLMS go beyond answering the query, they map the sibling possibilities that surround it.
The divergence gap: Clarification vs. exploration
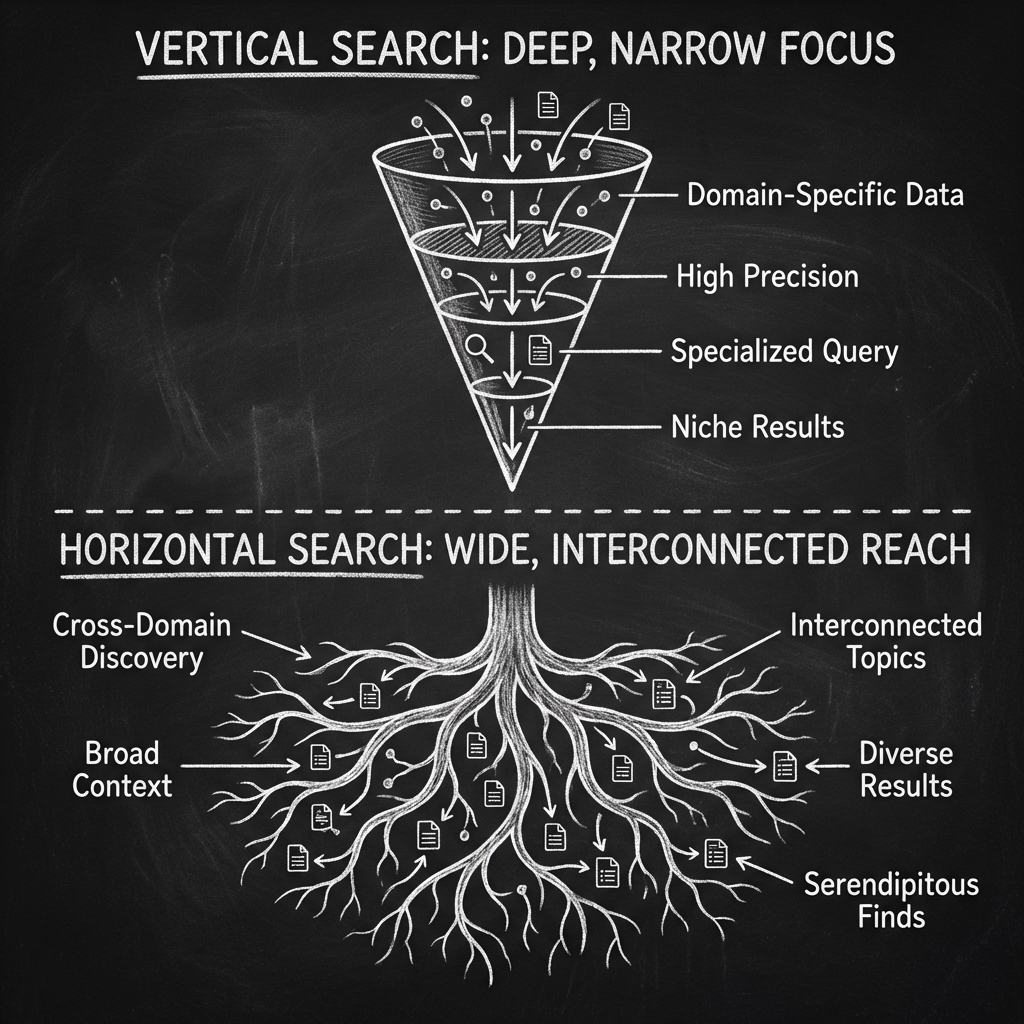
Current conversational search systems suffer from a Vertical Bias. They assume every query requires a specific sub-intent. If a user searches for “Cartier women’s watches,” the system suggests “price” or “style.”
This is Search Clarification. Search clarification is a system that assumes the user wants to drill down into a specific sub-topic.
Exploratory search is the opposing behavior where a user seeks to compare parallel options. Instead of looking deeper at one watch, the user wants to see competing brands or matching accessories. I understand that traditional search engines fail here because they struggle to predict these lateral moves without specific structural data.
Users often possess exploratory Needs. A user looking at a watch often wants to compare it to a “Rolex” or explore “Bracelets.” By forcing the user deeper into the current silo, the system ignores the natural human desire to compare and explore parallel concepts. We must stop trapping users in the vertical funnel and enable horizontal movement.
The Choice Reduction Mandate explains how defining clear boundaries helps the AI understand your niche.
The hidden signal: Utilizing HTML list structures
HTML list mining is the extraction of semantic relationships from the <li> and <select> tags found in website code. The research reveals that the most accurate source of parallel information is not the paragraph text, but the navigation menus and lists on high-ranking pages.
Recognition that a retail website naturally groups “sibling” products together in its code. When a search engine reads these lists, it learns that Rolex is a peer to Cartier, or that a bracelet is a parallel accessory to a watch.
The answer to user intent hides in the HTML structure. The research reveals that parallel information naturally congregates in list Structures (<li> tags) and select menus on authoritative websites.
We identify “Sibling Terms” by scraping these specific code elements. On a retail site, the navigation menu lists “Watches” next to “Bracelets.”
These physical proximities in the code signal semantic proximity in the Knowledge Graph. The algorithm extracts these list items to understand that “Rolex” is a peer to “Cartier,” not a sub-type.
The Three-stage generation methodology
The generation pipeline is the sequence of technologies that converts raw HTML data into intelligent user suggestions. The researchers propose a specific flow moving from rigid rules to flexible AI.
I define the three stages simply. First, Rule-Based Reformulation scrapes the top search results to find parallel terms. Second, a Neural Model refines these terms using pattern recognition. Third, a Large Language Model polishes the final output to ensure it sounds natural to the user.

Credit: Mining Exploratory Queries for Conversational Search, Liu et al., WWW ‘24.
The Contextual necessity: Why LLMs need structure
Retrieval-augmented generation is the practice of feeding an AI specific data to improve its accuracy. The study proves that even advanced AI models like GPT-3.5 struggle to guess parallel topics on their own.
I observe that the AI performs significantly better only when it is provided with the extracted list items from the first stage. This confirms that structural data is the bridge that allows the AI to understand the relationship between different entities.
Rule-Based Parallel Reformulation (RPR): The researcher scrapes the top 50 search results and extracts items found in list structures. They replace terms in the original query with these extracted list items to create immediate candidates.
Neural Generation (EQG): The researchers utilize a BART-based encoder-decoder model trained with Multi-Task Learning. This model performs two simultaneous tasks: generating the exploratory query and classifying “distractor” groups. This classification step is critical—it filters out hierarchical terms (parent/child relationships) to ensure the system only suggests true parallel siblings.
LLM-Based Generation (LLMG): They prompt an advanced Large Language Model to generate queries. The critical insight is that the LLM performs significantly better when we first feed it the extracted list data. Structure grounds the AI.
The semantic imprint: Implications for site architecture
Semantic HTML is the practice of using the correct code tags to describe the type of content on a page. This research confirms that how you code your lists and menus directly impacts how an AI understands your product ecosystem.
You must architect your web entity to feed this exploratory engine. The research proves that AI agents struggle to generate useful parallel suggestions from plain text alone; they rely on structured lists.
The Protocol:
- Use HTML lists: Do not bury parallel concepts in paragraphs. Use bullet points (
<li>) and tables to list competitors, product variants, and related categories.
Group sibling entities: Place related entities in close proximity within the DOM structure.
Define the relationship: Ensure your navigation menus clearly delineate between “Parent” categories and “Sibling” options.
I advise that site owners must strictly organize their content hierarchies. If you do not group parallel products in clear list structures, you deny the search engine the data it needs to recommend your brand as an alternative to your competitor on an AI Chatbot or AI Search.
This connects the concept of HTML lists to the broader Knowledge Graph and Orchestrating the Knowledge Graph.
Share Article
If this article helped you, please share it with others!
Some content may be outdated