
 Melky
Melky 
The birth of RankBrain and the power of Context Vectors

In 2015, Google announced RankBrain, and the SEO world was thrown into a frenzy.
It was described as a “machine-learning artificial intelligence system” that could understand ambiguous queries.
For many, it felt like the search engine had suddenly developed a consciousness. The reality, however, is that RankBrain was not a beginning, but a destination, a journey that started years earlier with the concepts we’ve already discussed.
As we continue our exploration of Koray Gübür’s presentation, “Semantic Search Engine & Query Parsing,” we arrive at the missing link between the query clustering of the early 2000s and the advanced AI of today.
That link is a technology called Context Vectors.
This is where Google’s Algorithm brain truly began to form.
This is part of the “AI Search? It’s Just Search, Rebranded” series, exploring the evolution of semantic search.
From Word Clusters to Word Relationships
In our previous article, we discussed how “Midpage Query Refinements” used clusters to group similar queries and documents.
But this approach has limitations. It can tell you that “apple” and “iPhone” belong in the same bucket, but it doesn’t understand the relationship between them.
The jump to the next level of understanding required a shift from simple grouping to mathematical modeling.
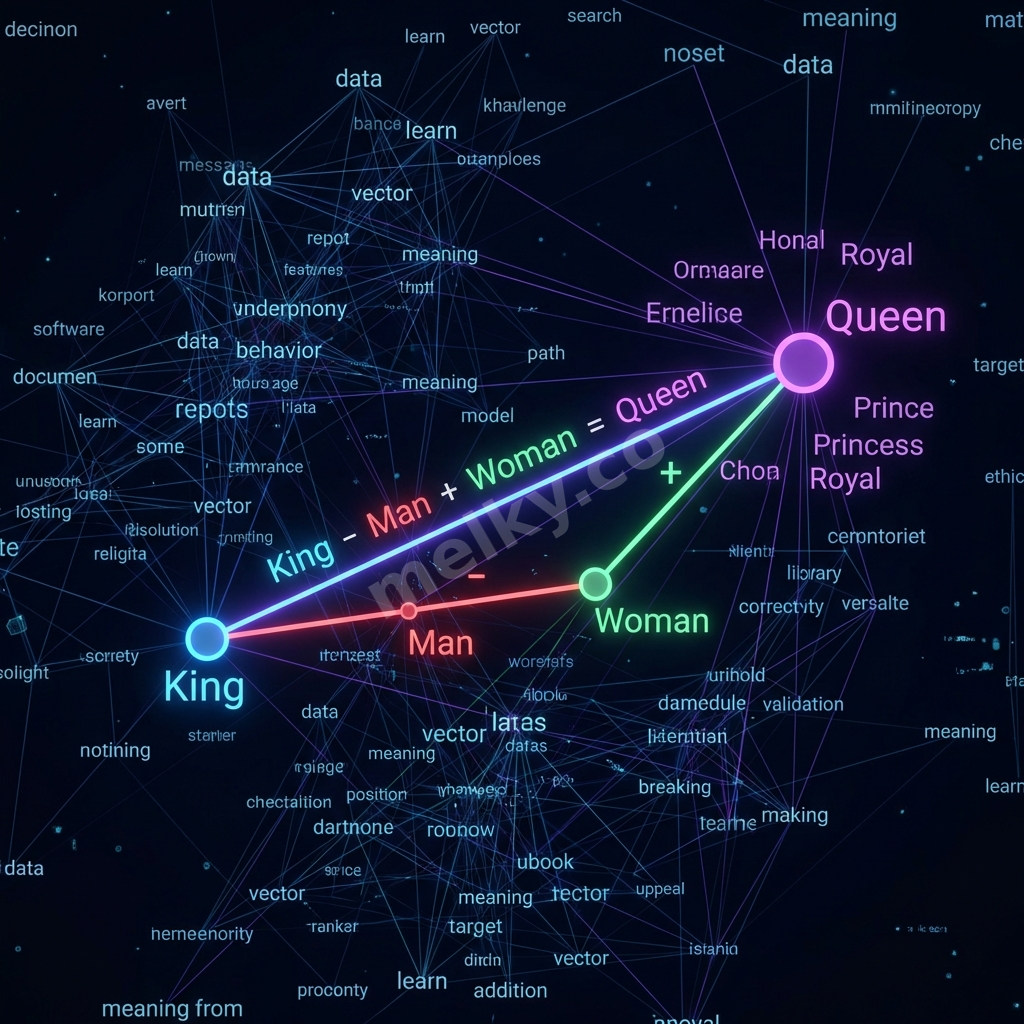
This is where the distinction between Word Vectors and Context Vectors becomes crucial.
-
Word Vector: A mathematical representation of a single word. In a vector space, words with similar meanings (like “king” and “queen”) are located close to each other.
-
Context Vector: This is far more powerful. It’s not just about one word; it’s a representation of combinations of words within a specific Contextual Domain.
Think of a “Contextual Domain” as a subject area, like “Medicine,” “Finance,” or “Automotive.”
The Context Vector for the word “bank” would be completely different in the domain of “Finance” (where it relates to “money,” “account,” “loan”) than in the domain of “Geography” (where it relates to “river,” “shore,” “erosion”).
This concept is detailed in the “Context-Vectors” patent.
Context-Vectors patent describes a system that:
-
Divides the Universe into Domains: It carves up the web’s information into distinct topical areas.
-
Builds a Vocabulary List for Each Domain: It identifies the unique terms and phrases that define that domain.
-
Calculates a Macro Context: It determines which domains are dominant for any given topic or entity.
-
Counts Occurrences: It tracks how often terms appear together within that domain, strengthening their relational bond.
This is the beginning of RankBrain.
By understanding that “cold” in the “Medicine” domain means a virus, while “cold” in the “Meteorology” domain means temperature, the search engine can finally grasp meaning, not just words.
RankBrain: The Application of Context Vector Technology
When Google explains RankBrain, they often use the example of a query like, “What’s the title of the consumer at the highest level of a food chain?”
A traditional keyword-based system would fail. But a system built on Context Vectors would thrive.
It would recognize “consumer,” “level,” and “food chain” as terms belonging to the “Biology” contextual domain.
Within that domain, it has learned the mathematical relationship between those terms and the concept of “predator.” It doesn’t match keywords; it finds the closest concept in vector space.
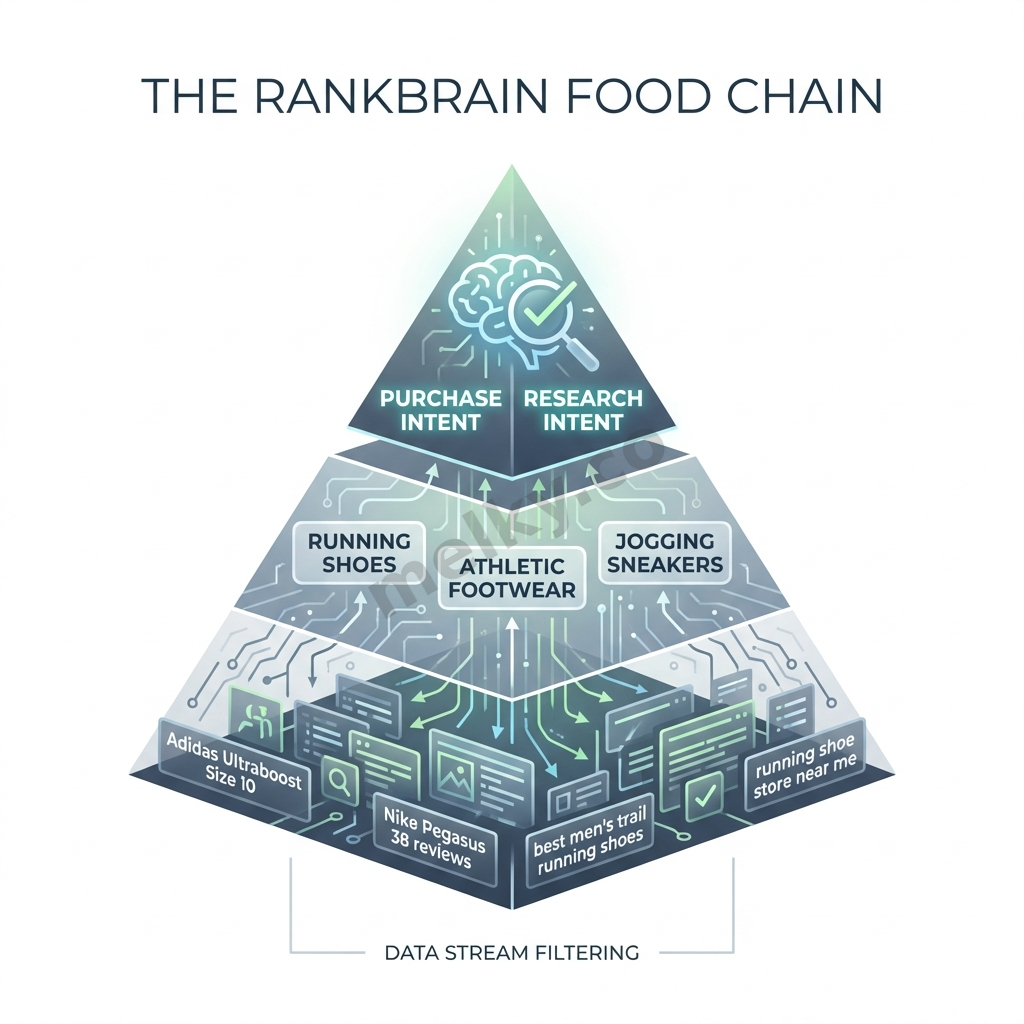
Koray’s insight is stark and clear: “Midpage Query Refinements and Query-Document Logical Pairs with Centroids and Clusters are the beginning of RankBrain. Context-Vectors were the second step for completing the journey”.
This isn’t just theory.
The patent explicitly mentions using these vectors to handle things like:
-
Question Generation: Using topical entries to generate questions and answers (the foundation of Featured Snippets).
-
Differentiating Sub-contexts: Understanding the nuance between “differentiating skin cancer” and “differentiating a math equation.”
-
Identifying Dominant Knowledge Domains: Recognizing that a query about “apple” is more likely about technology than fruit, based on modern search behavior.
What This Means for Your SEO Strategy
Understanding Context Vectors should fundamentally change how you build web pages.
-
Context is King, Not Content: It’s no longer enough to write a long article. Your content must be steeped in the correct contextual domain. A post about “lead generation” for plumbers must use the language, entities, and concepts of the plumbing industry, not just generic marketing terms.
-
Entity Co-occurrence Matters: Mentioning related entities strengthens your context. An article about Steve Jobs becomes contextually richer when it also mentions Apple, Pixar, NeXT, and Jony Ive. This helps Google place your content in the correct, highly specific “Macro Context.”
-
Answer the Implied Question: RankBrain is designed to solve novel queries. Your goal should be to create content that answers not just the explicit keyword, but the underlying intent that the vector model would connect it to. If you are writing about “fixing a leaky faucet,” you should also address related concepts like “plumber’s tape,” “water pressure,” and “common valve types” because those terms are part of the same Context Vector.
RankBrain was never magic. It was the application of a decade of research into understanding the mathematical relationships between words within specific contexts.
By aligning our content with these contextual domains, we aren’t just optimizing for an algorithm; we are mirroring the very way a search engine learned to think.
Next, we’ll explore how BERT, MuM, and LaMDA supercharge this foundation, taking semantic understanding to unprecedented levels.
Share Article
If this article helped you, please share it with others!
Some content may be outdated